获取url的方法如下:在文件管理器中找到需要打开的url文件,并选择打开方式为“文本”。用“文本”方式打开后,会弹出查看工具,点击使用HTML查看器打开。最底下一行是网络地址,从“=”号后面开始选择,直接复制。
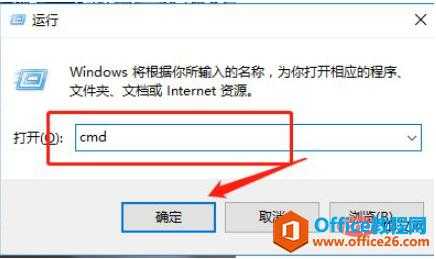
进入运行界面,windows+R进入运行界面,输入cmd后点击确定。输入nslookup,在命令窗口输入nslookup,然后空格,回车。复制网址进行查看,将要查看的网址粘贴到命令行,回车,在非权威应答下就是要查看网站的ip。
打开浏览的网页,点击你想查看url的网页信息。网站地址栏就是对于的url地址路径信息。如果还需查看url的详细ip地址,可windows+R”组合键,输入cmd回车。
1、抓取 读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
2、把搜索范围限定在特定站点中——site 把搜索范围限定在网页标题中——intitle 把搜索范围限定在url链接中——inurl 把搜索范围限定在网页标题中——intitle 网页标题通常是对网页内容提纲挈领式的归纳。
3、搜索引擎内部有一个URL索引库,所以搜索引擎蜘蛛从搜索引擎的服务器上沿着搜索引擎已有的URL抓取一个网页,把网页内容抢回来。页面被收录后,搜索引擎会对其进行分析,将内容从链接中分离出来,暂时将内容放在一边。
4、抓取 搜索引擎为想要抓取互联网站的页面,不可能手动去完成,那么百度,google的工程师就编写了一个程序,他们给这个自动抓取的程序起了一个名字,蜘蛛(也可以叫做“机器人”或者“网络爬虫”)。
5、**抓取(Crawling)**:搜索引擎会使用自动化的程序,称为网络爬虫或蜘蛛,来浏览互联网上的网页。爬虫从一个网页到另一个网页,通过跟踪超链接和索引文本内容,将网页的内容下载到搜索引擎的数据库中。
6、搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链接,像蜘蛛在蜘蛛网上爬行一样,所以被称为“蜘蛛”也被称为“机器人”。搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容。
获取内容用 file_get_contents() 或 curl 函数库。具体可以看手册。
在当前网页echo出变量$_SERVER[HTTP_HOST]即可获取域名或主机地址。在当前网页echo出变量$_SERVER[PHP_SELF]即可获取网页地址。在当前网页echo出变量$_SERVER[QUERY_STRING]即可获取网址参数。
刚吃完午饭吧,来帮你实现一下吧。记得加分哦。



