1、爬行与抓取(crawling & indexing)爬行:搜索引擎使用自动程序,通常称为“爬虫”或“蜘蛛”(如google的googlebot),它们通过跟踪网页上的超链接在网络中不断发现新的网页和更新内容。
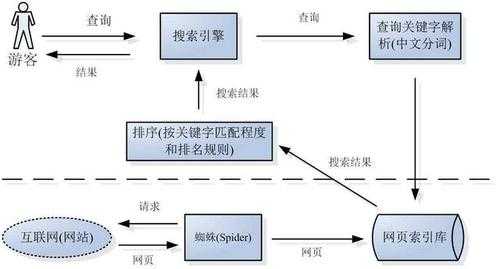
2、搜索引擎的工作原理总共有四步:第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。
3、网页抓取 Spider每遇到一个新文档,都要搜索其页面的链接网页。搜索引擎蜘蛛访问web页面的过程类似普通用户使用浏览器访问其页面,即B/S模式。
1、解析:搜索引擎基本结构一般包括:搜索器、索引器、检索器、用户接口等四个功能模块。
2、搜索引擎大致由搜索系统、索引系统、检索系统三个部分组成。爬虫(Spider)或网络蜘蛛:爬虫是搜索引擎的核心组成部分之一,它负责在互联网上自动抓取网页内容。
3、搜索引擎的4个组成部分包括爬虫、索引器、排序算法和搜索器,其各部分的主要功用如下:爬虫(Spider):也被称为机器人或网页蜘蛛,负责在互联网上抓取和收集网页信息。
搜索引擎的工作原理是从互联网上抓取网页,建立索引数据库,在索引数据库中搜索排序。
索引系统。。爬虫将网页抓取之后就会有去重去躁然后建立索引。
首先我们要知道提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内定向向你的网站派出蜘蛛程序,扫描你的网站并将有关信息存入数据库,以备用户查询。
搜索引擎机器人简称(蜘蛛)先收集你网站的信息然后到返还给一个系统(工作站)处理你的信息。
搜索引擎的原理是数据收集、建立索引数据库、索引数据库中搜索和排序。搜索引擎的自动信息收集功能分为两种类型,一种是定期搜索,即每隔一段时间,搜索引擎就会主动发送一个“蜘蛛”程序来搜索特定IP地址范围内的互联网站点。
1、搜索引擎的原理是数据收集、建立索引数据库、索引数据库中搜索和排序。搜索引擎的自动信息收集功能分为两种类型,一种是定期搜索,即每隔一段时间,搜索引擎就会主动发送一个“蜘蛛”程序来搜索特定IP地址范围内的互联网站点。
2、搜索引擎的工作原理总共有四步:第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。
3、爬行与抓取(crawling & indexing)爬行:搜索引擎使用自动程序,通常称为“爬虫”或“蜘蛛”(如google的googlebot),它们通过跟踪网页上的超链接在网络中不断发现新的网页和更新内容。



