简单理解,百度蜘蛛又名百度爬虫,主要的工作职能是抓取互联网上现有的URL,并对页面质量进行评估,给出基础性的判断。
Spider也就是大家常说的爬虫、蜘蛛或机器人,是处于整个搜索引擎最上游的一个模块,只有Spider抓回的页面或URL才会被索引和参与排名。
搜索引擎“蜘蛛”指的是网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取信息的程序或者脚本。
①、高级蜘蛛。高级蜘蛛负责去爬行权重比较高的网站,高级蜘蛛有专门的权限,就是秒收。这就是为什么你去权重比较高的论坛发帖,会被搜索引擎直接秒收了。
内容及时更新性:搜索引擎每天会定期更新爬行网站,如果搜索引擎第一天爬行您的网站没有新的内容,可 能搜索引擎第二次还会尝试看有没有新鲜的东西。不过这样没有几天下去,搜索引擎也不会再来。
关键词研究:这是搜索引擎SEO的第一步,目的是确定网站的关键词策略。通过研究相关的关键词,找出用户搜索的热门词汇,并了解竞争对手的关键词选择和使用情况。
搜索引擎收录网站内容的过程中,其实含有更复杂的逻辑,这里广本宝就不做衍生了。
一般来说,URL每一个“/”就代表一层,权重越低,层次越深,搜索引擎抓取越困难,排名也会越差。图片优化 图片优化应站在用户视觉、适合蜘蛛抓取等角度来考虑,图片太大或太小都不好。
1、索引数据库,索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。简单的来说,就是把【抓取】的网页放进数据库。
2、蜘蛛抓取的页面文件分解、分析,并以巨大表格的形式存入数据库,这个过程即是索引(index).在索引数据库中,网页文字内容,关键词出现的位置、字体、颜色、加粗、斜体等相关信息都有相应记录。
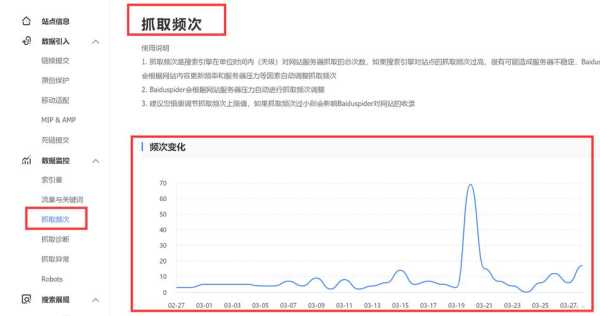
3、先打开百度站长平台,并找到“抓取频次”这个工具。目录为工具→网站分析→抓取频次。首先是可以看到自己的抓取统计,包含抓取频次、抓取时间、抓取状态统计等等。
4、百度蜘蛛抓取规则 对网站抓取的友好性 百度蜘蛛在抓取互联网上的信息时为了更多、更准确的获取信息,会制定一个规则最大限度的利用带宽和一切资源获取信息,同时也会仅最大限度降低对所抓取网站的压力。
5、用户在查询信息时,可以选择按照关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟全文搜索引擎一样,也是根据信息关联程度排列网站。
6、蜘蛛来到网站进行抓取,首先看的是网页的头部信息,若是蜘蛛发现有和索引库中一样的标题,则食欲就大减。文章的内容应具有唯一性,站内不要有太多的相同内容,站外相同也需求有唯一性。
蜘蛛喜欢的行为四:距离首页点击距离。这里说的距离首页点击距离一般是因为首页的权重最高,蜘蛛爬行到首页次数也最多,每通过一次链接叫一次点击,距离首页点击距离越近代表了页面权越重高,蜘蛛就喜欢这些短距离高权重的页面。
也就是比如百度蜘蛛找到一个链接,沿着这个链接爬行到一个页面,然后沿着这个页面里面的链接爬行&hellip&hellip这个类似于蜘蛛网和大树。这个理论虽然正确,但不准确。
深度链接 深度优先指当蜘蛛发现一个链接时,它就会顺着这个链接指出的路一直向前爬行,直到前面再也没其他链接,这时就会返回第一个页面,然后会继续链接再一直往前爬行。
第一步:爬行 搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链接,像蜘蛛在蜘蛛网上爬行一样,所以被称为“蜘蛛”也被称为“机器人”。
对于seoer来说,网站的第一步就是解决收录问题,我们每天都在更新,可有时就是不收录。我们要想得到收录和蜘蛛的青睐,你就要懂得蜘蛛的爬行原理和规律。
也就是比如百度蜘蛛找到一个链接,沿着这个链接爬行到一个页面,然后沿着这个页面里面的链接爬行&hellip&hellip这个类似于蜘蛛网和大树。这个理论虽然正确,但不准确。
网站权重:权重越高的网站百度蜘蛛会更频繁和深度抓取 网站更新频率:更新的频率越高,百度蜘蛛来的就会越多 网站内容质量:网站内容原创多、质量高、能解决用户问题的,百度会提高抓取频次。
通常百度蜘蛛抓取规则是:种子URL-待抓取页面-提取URL-过滤重复URL-解析网页链接特征-进入链接总库-等待提取。
搜索引擎抓取的页面文件与用户浏览器得到的完全一样,抓取的文件存入数据库。
服务器要稳定,也就是一定要给蜘蛛营造一个好的爬行的环境,因为蜘蛛一旦碰上死链就会直接走掉,如果服务器不稳定,可能蜘蛛转一圈,一个页面还没有抓取就迫不及待要走了。
这个策略是由调度来计算和分配的,百度蜘蛛只负责抓取,权重优先是指反向连接较多的页面的优先抓取,这也是调度的一种策略,一般情况下网页抓取抓到40%是正常范围,60%算很好,100%是不可能的,当然抓取的越多越好。
搜索引擎在对链接进行分析后,并不会马上派蜘蛛去抓取,而是将链接和锚文本记录到URL索引数据库中进行分析、比较和计算,最后放入URL索引数据库中。进入URL索引库后,会有蜘蛛抓取。
抓取 读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
对于新网站来说,想要让蜘蛛爬虫进入到网站,最好的方法就是通过外链的形式,因为蜘蛛爬虫对新网站不熟悉也不信任,通过外链可以让蜘蛛爬虫顺利的进入到网站中,从而增加友好性。



