工作原理 抓取网页 每个独立的搜索引擎都有自己的网页抓取程序(spider)。Spider顺着网页中的超链接,连续地抓取网页。被抓取的网页被称之为网页快照。
搜索引擎的工作原理总共有四步:第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。
工作原理 抓取网页 每个独立的搜索引擎都有自己的网页抓取程序(spider)。Spider顺着网页中的超链接,连续地抓取网页。被抓取的网页被称之为网页快照。
搜索引擎的工作原理:搜集信息 搜索引擎的信息搜集基本都是自动的。搜索引擎利用称为网络蜘蛛的自动搜索机器人程序来连上每一个网页上的超链接。
搜索引擎是一个对互联网信息资源进行搜索整理和分类,并储存在网络数据库中供用户查询的系统,包括信息搜集、信息分类、用户查询三部分。
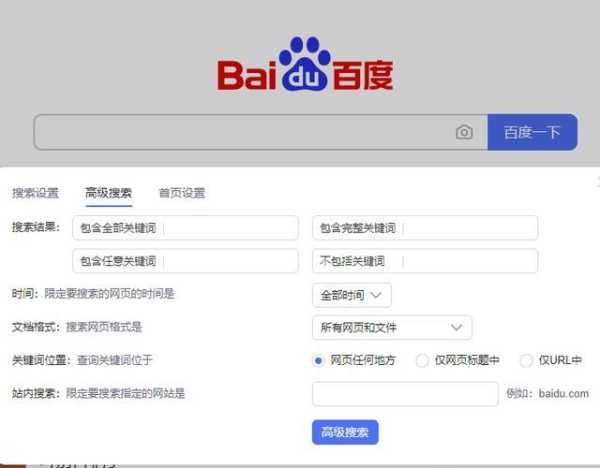
。首先,记下你需要搜索的网站的网址。URL显示在网页标题的下方,通常以http://或https://开头。这里,我们需要的网站以两个斜线开头。接下来打开搜索软件,点击右上角的设置:“高级搜索”按钮。
网站怎么找具体步骤如下:工具:联想电脑。首先在电脑的左下角的开始电脑小图标,也可以点击键盘上的小窗口按键。点击电脑开始图标后会弹出一个菜单,在菜单中会有一个输入框可以输入名称,来搜索程序或文件。
网页抓取 Spider每遇到一个新文档,都要搜索其页面的链接网页。搜索引擎蜘蛛访问web页面的过程类似普通用户使用浏览器访问其页面,即B/S模式。
首先,记下你需要搜索网站的网址,网址显示在网页标题下方,通常是http://或者https://开头,这里我们需要的网站是从两个斜杠后开始的。接下来打开搜索软件,点击右上角的设置”高级搜索“按钮。
搜索引擎的工作原理主要就是四个步骤:爬行,抓取,检索,显示。
1、工作原理 抓取网页 每个独立的搜索引擎都有自己的网页抓取程序(spider)。Spider顺着网页中的超链接,连续地抓取网页。被抓取的网页被称之为网页快照。
2、搜索引擎的工作原理总共有四步:第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。
3、工作原理 抓取网页 每个独立的搜索引擎都有自己的网页抓取程序(spider)。Spider顺着网页中的超链接,连续地抓取网页。被抓取的网页被称之为网页快照。
1、搜索引擎的工作原理总共有四步:第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。
2、搜索引擎(search engine)是指根据一定的策略、运用特定的计算机程序搜集互联网上的信息,在对信息进行组织和处理后,并将处理后的信息显示给用户,是为用户提供检索服务的系统。
3、搜索引擎的工作原理:搜集信息 搜索引擎的信息搜集基本都是自动的。搜索引擎利用称为网络蜘蛛的自动搜索机器人程序来连上每一个网页上的超链接。
4、搜索引擎是一个对互联网信息资源进行搜索整理和分类,并储存在网络数据库中供用户查询的系统,包括信息搜集、信息分类、用户查询三部分。
5、和元搜索引擎(Meta Search Engine)。因为目录索引虽然有搜索功能,但从严格意义上算不上是真正的搜索引擎,只是一个目录列表而已。用户完全可以不用进行关键词(Keywords)查询,仅靠分类目录也可找到需要的信息。
1、搜索引擎的工作原理总共有四步:第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。
2、工作原理 抓取网页 每个独立的搜索引擎都有自己的网页抓取程序(spider)。Spider顺着网页中的超链接,连续地抓取网页。被抓取的网页被称之为网页快照。
3、工作原理 爬行:搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链接,像蜘蛛在蜘蛛网上爬行一样,所以被称为“蜘蛛”也被称为“机器人”。



