索引 索引就是帮助程序进行快速查找的。大家都用过英汉词典。字典前边的按照单词首字母排列的部分就是索引。搜索引擎也一样。这里要介绍第一个最重要的数据结构:反转列表。
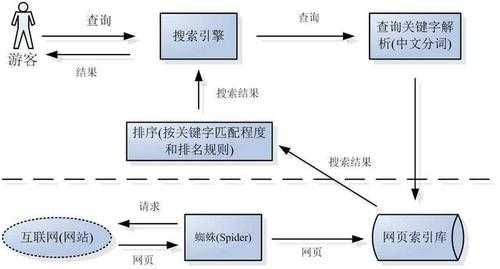
第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。第二步:抓取存储,搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。
第一步:明确所要查找的资料的主题,并确定相关主题词(及搜索时所使用的词)。第二步:根据不同的需要选择不同的搜索引擎。第三步:匹配主题词,并搜索资料。
搜索引擎的工作原理主要就是四个步骤:爬行,抓取,检索,显示。
网页抓取 Spider每遇到一个新文档,都要搜索其页面的链接网页。搜索引擎蜘蛛访问web页面的过程类似普通用户使用浏览器访问其页面,即B/S模式。
搜索引擎的工作过程,一般分为五个步骤:(1)从互联网上抓取网页,利用能够从互联网上自动收集网页的网络蜘蛛程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。
1、爬行与抓取(crawling & indexing)爬行:搜索引擎使用自动程序,通常称为“爬虫”或“蜘蛛”(如google的googlebot),它们通过跟踪网页上的超链接在网络中不断发现新的网页和更新内容。
2、关键词搜索:这是最常见的搜索策略,用户通过在搜索引擎中输入关键词或短语来寻找相关信息。搜索引擎会根据这些关键词在其索引中找到相关的结果。 高级搜索:许多搜索引擎提供高级搜索选项,允许用户更精确地过滤结果。
3、搜索引擎按其工作方式主要可分为三种,分别是 全文搜索引擎 (Full Text Search Engine)、目录索引 类搜索引擎(Search Index/ Directory )和 元搜索引擎 (Meta Search Engine)。
4、在数字世界里,搜索引擎是我们探索信息的得力助手。根据其工作方式,搜索引擎主要可以分为三大类:全文搜索引擎、目录索引类搜索引擎以及元搜索引擎。本文将为您详细介绍这三种搜索引擎的工作原理。
5、搜索引擎的工作过程是一个复杂的过程,通常包括以下步骤: **抓取(Crawling)**:搜索引擎会使用自动化的程序,称为网络爬虫或蜘蛛,来浏览互联网上的网页。
6、搜索引擎的工作原理总共有四步:第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。
1、搜索引擎的工作原理总共有四步:第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链 接,所以称为爬行。
2、搜索引擎的基本原理主要包括以下三个步骤:爬行和抓取:搜索引擎通过爬虫程序访问互联网上的网页,并收集这些网页的信息。
3、搜索引擎是一个对互联网信息资源进行搜索整理和分类,并储存在网络数据库中供用户查询的系统,包括信息搜集、信息分类、用户查询三部分。
4、搜索引擎的工作原理简单来说可以分为三步:信息采集模块 信息采集器是一个可以浏览网页的程序,被形容为“网络爬虫”。



